Coach Spotter
What is the challenge in text-to-SQL?
Post the introduction of LLMs (large language models), many people think that adding an LLM on top of their datasets to perform text-to-SQL will solve their self-serve analytics requirements. When this approach is applied on a demo dataset with a handful of columns, it has also displayed impressive results. However, when the same stack is put to use on enterprise datasets, the results have been disappointing. The difference in the level of accuracy of LLMs on demo datasets and enterprise datasets can be explained by the following two factors:
-
Enterprise datasets are larger and more complex.
-
Business users asking questions don’t understand the semantics and context of the data.
Enterprise datasets
When it comes to enterprise datasets where the data is distributed across multiple tables, answering simple questions becomes challenging because it requires applying the correct set of joins and disambiguating between a large number of columns and values. This is where some of the following elements of our stack differentiate us from a simple text-to-SQL solution:
Our data modeling layer plays a critical role in giving analysts control over some of the key decisions (such as what joins to apply and how to join tables) which cannot be done by the LLM. Our usage-based ranking systems help the LLM pick the correct columns. Our patented technology helps you avoid chasm traps in the data model.
Business users
The second reason why the text-to-SQL approach doesn’t work on enterprise datasets is that neither the business users nor the LLM understands the semantics and context of the data. As a result, business users end up asking questions using terminology which doesn’t match with the underlying dataset.
The guidelines for modeling data sets are discussed in Spotter Worksheet/Model readiness. In these articles, we explore how you can attempt to enable business users to ask questions normally.
How training helps Spotter
Let’s consider an example to understand the problem raised about business users not understanding the semantics and context of the data. Let’s take a simple question to understand the problem here. ThoughtSpot is a Software as a Service product where customers have the option of deploying their own instance of ThoughtSpot. A common question our SRE team have is: “What is the number of active clusters ?”
When this question is asked directly to an LLM, we get the following answer. A close look reveals that the LLM has assumed that “active cluster” means Cluster Status =’running’. The LLM model has made an assumption that looks fair. However, this isn’t the answer our SRE team was expecting.
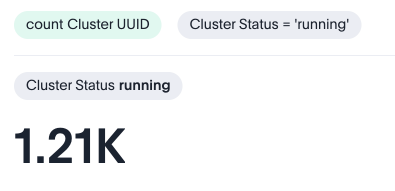
Based on our business context the number of “active cluster” is derived by the following approach: Exclude non-operations clusters: Cluster Status != deleted and Cluster Type != 'pot' . Note that LLM used cluster status = running , however we are excluding clusters instead. Remove the internal clusters: Account Status = customer and Account Name != thoughtspot…thoughtspot, inc are the filters used to remove internal clusters from the calculation of the active clusters.
Applying this definition of active cluster provides more acceptable results to the SRE team for our business context.
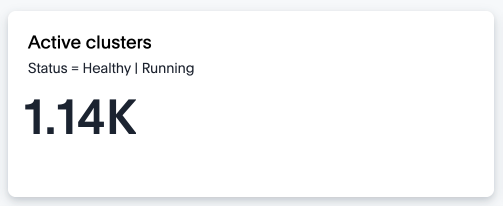
There are two key learnings we should derive from the example above :
-
While asking questions, business users may use terms like “Active clusters”, but they may not specify the instructions to define how the LLM must identify active clusters (for example, remove deleted and POT clusters status ; only include clusters where account status is set as customer and exclude thoughtspot account name). If these instructions were specified in the question, then the LLM would have provided the expected answer in the first attempt only. However, we cannot always expect users to specify this while asking questions because
-
Users won’t expect to specify the same definition every time they are asking a question about active clusters.
-
Users may not even have the required understanding of the data context to specify these definitions.
-
-
When users ask questions which have ambiguity, then the LLM models make some reasonable assumptions to generate an answer based on the information that is available in the public domain.
Training Spotter gives analysts a way to provide the information about semantics and context of the organization’s data. Training should be used to provide the analytical definition of the important business terms. Training Spotter helps in the following ways : Users don’t need to be overly descriptive while asking questions. As a result, more users will be comfortable in asking questions. LLM models don’t make assumptions about the key business terms used by the users while asking questions.
What you shouldn’t train in Spotter
As demonstrated in the previous section, training plays a key role in tuning Spotter for your audience. However, please be aware of the fact that Spotter answers are extremely sensitive to the training provided, and incorrect or confusing training may lead to inaccurate results too as our implementation is designed to treat the training as a trusted context about the dataset.
We don’t recommend the use of training for following aspects :
- Using training to overcome the Spotter’s limitations
-
While Spotter can answer a lot of questions using your dataset, it still has some limitations in the kind of questions it can answer at the moment. Spotter is targeted for business users and it performs well for most of the commonly asked questions in day-to-day operations.
However, we have observed that analysts sometimes try to train Spotter to perform some extremely complex analysis which isn’t directly supported yet. We do not recommend the use of training to teach Spotter how to do complex analysis, as such training may not scale in different business contexts.
We recommend that you should reach out to ThoughtSpot Support for guidance in such cases. Spotter is a rapidly evolving product and we are committed to improving out-of-box support for most day to day analysis. - Avoid conflicting training
-
We have observed that sometimes when two different users are asking the same question, the expected result may be different. For example, the regional head of the East region may define “my region” as region=east while the regional head for North may define “my region” as region=north.
At the moment, it is better to coach the users to specify the region explicitly instead of training Spotter, as the training will end up confusing the LLM more than helping it.
The same thing is also observed in training for dates. Let’s say your business is accustomed to looking at trends weekly instead of monthly. You may want to add a training “trend” to map this to date.weekly. However, if there are multiple date columns, then you cannot provide the same training for multiple dates.


