Group aggregation overview
Group_aggregate() is a general function which includes all functionality supplied by the other functions in this group. In other words, you can use the group_aggregrate() function alone to perform group_average(), group_count(), group_max(), group_min(), group_stddev(), group_sum(), group_unique_count(), or group_variance() calculations. For this reason, we primarily focus on the group_aggregate() function.
Group aggregation
ThoughtSpot’s group_aggregate() function allows you to aggregate to a level of detail that differs from the "search" level of detail, which is the level of detail at which your table or chart is displayed. You can use this function for many business use cases.
For example, in your table or chart, you may want each row to display the city name, the population of a city, and the population of the state. In this case the city represents the "search" level of detail, but you want to display values that are aggregated to the level of the state.
Alternatively, you may want to know the percentage of the state’s population that resides in each city. In this case you don’t want to display the state’s population, but you need that data in order to execute the computation (city population / state population). In both of these cases, the group_aggregate() function gives you the flexibility to aggregate to the state level of detail, even though your search is at the city level of detail.
The group_aggregate() function is powerful, but in order to harness its power you need to understand how to use it. In this tutorial, we use a very small data set that allows you to compute aggregates on the fly so that you can understand exactly how group_aggregate works. Once you understand the mechanics, you can apply it to your own business use cases.
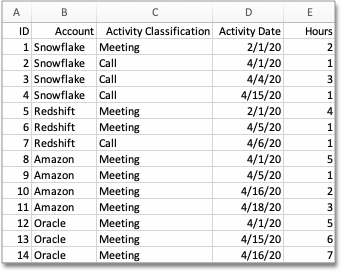
The data set we use is shown in the following image:
Click here to download this data set.
In this data set we have four accounts: Snowflake, Redshift, Amazon, and Oracle. Each account has activities associated with it: Meetings and Calls. Each meeting or call occurs on a particular date and for a specified number of hours. We use this data set for all of our examples. Using a small data set like this allows you to fully understand how group_aggregate() functions on your data.
Group_aggregate formula
The basic format of the group_aggregate formula is:
outer_aggregation(
group_aggregate(
inner_aggregation,
level_of_detail,
filters
)
)The following example uses the Meetings data set:
average(
group_aggregate(
sum(hours),
{Account},
{}
)
)This means, "Sum hours to the Account level of detail. If the level of detail specified by the search is coarser than Account, aggregate up by averaging. If the level of detail specified by the search is finer than Account, replicate the sum at the finer level of detail".
Now, let’s walk through each argument in the group_aggregate formula:
outer_aggregation(
group_aggregate(
inner_aggregation,
level_of_detail,
filters
)
)This applies the following set of steps to aggregate values based on the arguments in the group_aggregate function:
-
Apply row-level filters specified by <filters>.
-
Then apply the aggregation function <inner_aggregation> at the level of detail specified by <level_of_detail> to create the inner aggregation result.
-
Your final result depends on the level of detail of the search. If the search level of detail is:
-
the same as <level_of_detail>: the result is inner aggregation result
-
finer than <level_of_detail>: inner aggregation result is replicated at the finer search level of detail.
Consider a formula that calculates the population of the state. If you create a table that has one row for each city, the state population value replicates for each city row. In other words, you might have a column with state population and for every city in the state, the column would always show the city’s state population. You could use this in another formula to calculate the city’s population as a percentage of its state population.
-
coarser than <level_of_detail>: inner aggregation result is aggregated up to the coarser search level of detail using the aggregation specified by <outer_aggregation>.
While it is possible to omit outer_aggregation, we recommend you always include outer_aggregation in the definition of a group_aggregate formula. For more information on behavior when omitting outer_aggregation, see Omitting outer aggregation from your formula.
-
The arguments to group_aggregate are:
-
<inner_aggregation> is a function which aggregates a column. Examples are:
-
sum(hours): aggregate by returning the sum of the hours in the column.
-
if (sum(hours)) > 10 then 1 else 0: aggregate by summing the hours, and if the summed hours are greater than 10, returning a result of 1, else 0.
-
min(activity date): aggregate by returning the minimum of the values in the activity date column.
-
-
<level_of_detail> specifies the level of detail at which the inner aggregation should be applied. The level of detail can be specified independently of the query in the search bar, or can be combined with the attributes in the search bar to create a level of detail that adjusts based on what is in the search bar. Examples are:
-
{ account }: aggregate by applying the inner_aggregation function at a level of detail created by grouping by account.
-
{ account, activity classification }: aggregate by applying the inner aggregation function at a level of detail created by grouping by account and activity classification.
-
query_groups() + { activity classification }: aggregate by applying the inner aggregation function at a level of detail created by adding activity classification to the level of detail specified by the search bar. If the search bar already contains activity classification, this has no effect.
-
query_groups() - { activity classification }: aggregate by applying the inner aggregation function at a level of detail created by removing activity classification from the level of detail specified by the search bar. If the search bar does not contain an activity classification, this has no effect.
-
-
<filters> specifies filters that are applied to the return value. The filters can be independent of any filters in the search or they can include or exclude filters from the search bar. Examples are:
-
{activity classification = "meeting"}: apply a row-level filter to include only rows where activity classification is set to ‘meeting’
-
query_filters() : apply the filters specified in the search bar
-
Outer_aggregation is a simple aggregation function such as sum, avg, or min. As mentioned earlier in the article, it is recommended that you always include outer_aggregation in your definition of a group_aggregate() formula. Omitting it can lead to unexpected results that are difficult to understand unless you are an expert user of group_aggregate() functions.
In Basic use of group aggregation, we walk through a number of example use cases of group_aggregate, using our sample data set.


