Data caching
ThoughtSpot does all analysis against data in memory to help achieve fast results across millions and billions of records of data.
ThoughtSpot caches data as relational tables in memory. You can source tables from different data sources and join them together. ThoughtSpot has several approaches for getting data into the cluster.
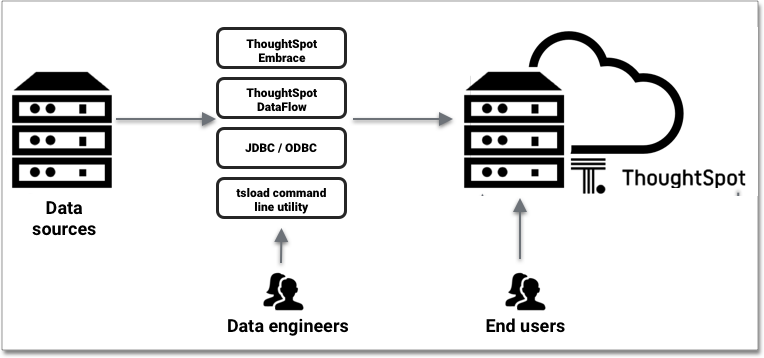
For cases where your company stores data externally, use connections to access and query your data. To cache your data within ThoughtSpot, you can load it directly using DataFlow, or the tsload command-line utility. JDBC and ODBC drivers are also available.
|
ThoughtSpot connections
If your company stores source data externally in data warehouses, you can use Connections to directly query that data and use ThoughtSpot analysis and visualization features, without moving the data into ThoughtSpot. While connections cache metadata, they do not cache the data itself within ThoughtSpot.
You can connect to the following external databases:

|
|
|
|
|
ThoughtSpot DataFlow
Dataflow is a capability in ThoughtSpot through which users can easily ingest data into ThoughtSpot from dozens of the most common databases, data warehouses, file sources, and applications. If your company maintains large sources of data externally, you can use DataFlow to easily ingest the relevant information, and use ThoughtSpot’s analysis and visualization features. After you configure the scheduled refresh, your analysis features are always up-to-date. DataFlow supports a large number of databases, applications, and file systems.
tsload
You can use the tsload command line tool to bulk load delimited data with very high throughput.
Finally, individual users can upload smaller (< 50MB) spreadsheets or delimited files.
We recommend the tsload approach in the following cases:
-
initial data load
-
JDBC or ODBC drivers are not available
-
there are large recurring daily loads
-
for higher throughput; this can add I/O costs
Choosing a data caching Strategy
The approach you choose depends on your environment and data needs. There are, of course, tradeoffs between different data caching options.
Many implementations use a variety of approaches.
For example, a solution with a large amount of initial data and smaller daily increments might use tsload to load the initial data, and then use the JDBC driver with an ETL tool for incremental loads.
Related information