Sync data from ThoughtSpot to Redshift
Sync to Redshift from an Answer
To create a sync to Redshift from an Answer, follow these steps:
-
Select the desired Answer from the Answers tab or the ThoughtSpot homepage. You must have Can manage sync permissions and view access to an Answer to create a sync.
-
In the upper-right corner of the Answer, click the more options menu icon
 . From the dropdown menu, select Sync to other apps, then choose Redshift.
. From the dropdown menu, select Sync to other apps, then choose Redshift. -
If this is the first sync you have created for Redshift, a pop-up authorization window appears. To give ThoughtSpot permission to send data to your Redshift account, select your account from the pop-up window.
-
Within ThoughtSpot, fill in the following parameters:
-
Edit the Pipeline name if needed. By default, this field populates with PL-[Answer Name].
-
If you have more than one Redshift destination set up, then the Destination field appears, and you will have to select a Redshift destination from the dropdown menu available. However, if no destinations have been set up before or if you have only one Redshift destination, the Destination field will not appear.
-
Select your Redshift Object from the dropdown menu.
-
Select Operation from the dropdown menu. You can choose between Insert and Upsert.
-
Map the Source and Destination columns from the dropdown menus provided. Note that the Source column refers to the column in ThoughtSpot, while the Destination column refers to the column in Redshift.
If you select Upsert as the operation, the External ID option appears as well, to the left of the Source and Destination columns. This option is only clickable if the Destination column is unique (for example, ID). For the external ID column, the source column values will be looked up against the destination column values. For matches on that column, the existing records in Redshift will be updated with the new source columns while records that don’t exist yet will be created and populated using the source column data.
-
-
By default, "Save and sync" is selected. Select Save to send your data to Redshift. Your data immediately appears in Redshift.
-
[Optional] To set up a repeated sync, click Schedule your sync and select your timezone. From the options provided, choose whether the sync will occur every:
-
n minutes. You can choose to schedule a sync every 5, 10, 15, 20, 30, or 45 minutes.
-
n hours.
-
n days at a selected time. Note that you can choose not to send an update on weekends.
-
week at a selected time and day.
-
n months at a selected time and date.
-
| Any sync over 50,000 rows may result in an execution timeout. For optimal performance, keep your sync to below 50,000 rows. If you’re syncing a large number of rows and the sync fails, try applying filters like date filters to make your dataset smaller and then sync. |
Sync to Redshift from a Custom SQL View
To sync to Redshift from a custom SQL view, follow these steps:
-
Navigate to your SQL view by selecting the Data tab and searching from the Data Workspace home page. Select the SQL view name.
-
In the upper-right corner, click the more options menu icon
and select Sync to Redshift. -
If this is the first sync you have created for the selected app, an authorization page appears. To give ThoughtSpot permission to send data to your Redshift account, click Sign in with Redshift, select your account, and click Allow.
-
Fill in the following parameters:
-
Edit the Pipeline name if needed. By default, this field populates with PL-[Answer Name].
-
If you have more than one Redshift destination set up, then the Destination field appears and you have to select a Redshift destination from the dropdown menu available. However, if no destinations have been set up before or if you have only one Redshift destination, the Destination field will not appear.
-
Select Object from the dropdown menu.
-
Select Operation from the dropdown menu. You can choose between Insert and Upsert.
-
Map the Source and Destination columns from the dropdown menus provided.
If you select Upsert as the operation, the External ID option appears as well, to the left of the Source and Destination columns. This option is only clickable if the Destination column is unique (for example, ID). For the external ID column, the source column values will be looked up against the destination column values. For matches on that column, the existing records in Redshift will be updated with the new source columns while records that don’t exist yet will be created and populated using the source column data.
-
-
By default, "Sync and save" is selected. Select Save to send your data to Redshift. Your data immediately appears in Redshift.
-
[Optional] To set up a repeated sync, click Schedule your sync and select your timezone. From the options provided, choose whether the sync will occur every:
-
n minutes. You can choose to schedule a sync every 5, 10, 15, 20, 30, or 45 minutes.
-
n hours.
-
n days at a selected time. Note that you can choose not to send an update on weekends.
-
week at a selected time and day.
-
n months at a selected time and date.
-
| Any sync over 50,000 rows may result in an execution timeout. For optimal performance, keep your sync to below 50,000 rows. If you’re syncing a large number of rows and the sync fails, try applying filters like date filters to make your dataset smaller and then sync. |
Failure to sync
A sync to Redshift can fail due to multiple reasons. If you experience a sync failure, consider the following causes:
-
The underlying ThoughtSpot object was deleted.
-
The underlying Redshift object was deleted.
-
The column name was changed in either ThoughtSpot or Redshift, making it different to the column name setup in the mapping.
-
There are data validation rules in Redshift which only allow data with only a certain data type to be populated in the Redshift fields, but the columns being mapped onto Redshift from ThoughtSpot do not have the same or allowable data type.
-
There is a mandatory field in Redshift which has not been mapped onto as a destination column when setting up the mapping in ThoughtSpot.
Manage pipelines
While you can also manage a pipeline from the Pipelines tab in the Data Workspace, accessing the Manage pipelines option from an Answer or view displays all pipelines local to that specific data object. To manage a pipeline from an Answer or view, follow these steps:
-
Click the more options menu icon
and select Manage pipelines. -
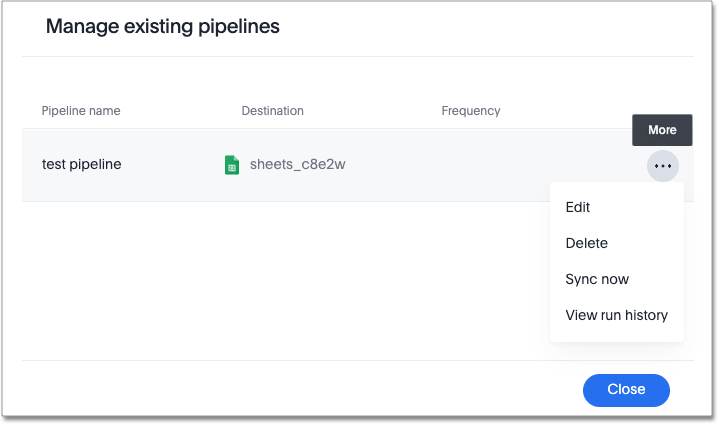
Scroll to the name of your pipeline from the list that appears. Next to the pipeline name, select the more options icon
. From the list that appears, select:-
Edit to edit the pipeline’s properties. For example, for a pipeline to Google Sheets, you can edit the pipeline name, file name, sheet name, or cell number. Note that you cannot edit the source or destination of a pipeline.
-
Delete to permanently delete the pipeline.
-
Sync now to sync your Answer or view to the designated destination.
-
View run history to see the pipeline’s Activity log in the Data Workspace.
-
Related information


