Sync data through Snowflake connection
After using ThoughtSpot DataFlow to establish a connection to a Snowflake database, you can create automatic data updates, to seamlessly refresh your data.
To sync your data, perform these tasks:
Select table
-
Immediately after creating a new connection, the connection detail page appears.
You can fill out this information immediately, or return to it at a later stage, by clicking on the connection name in the list of connections.
-
On the connection detail page, click Add table sync.
-
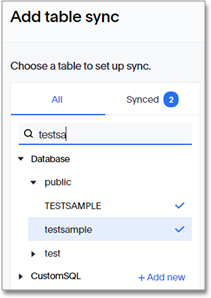
In the Add table sync interface, on the database selector, scroll to select and open the source database.
Note that you can search for the database by name.
-
From the database, select the table you plan to sync. You can also search for the table by name.
Note that if you use multiple tables, you have to repeat these steps for each table.
Before confirming that you plan to sync a particular table, examine it to ensure that it has the right information: the correct data types, and reasonable sample data.
For large tables, use the search bar to search column names.
Dataflow now supports case-sensitive table names. You can create multiple syncs using different tables with the same name from the same connection and database.
-
Click Setup sync.
Specify sync schedule
Immediately after creating a new connection, the connection detail page appears.
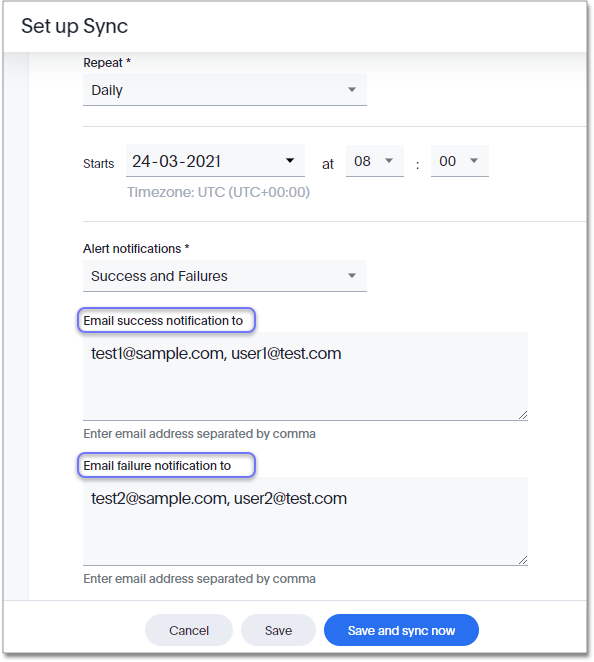
When you create a sync schedule, you have the following scheduling options:
After you specify the sync schedule, click Save and sync now. This action saves the schedule, and starts the data sync immediately.
Alternatively, if you click Save, the system saves the schedule, but does not sync the data. This gives you the opportunity to fine-tune the column mapping between external data sources and tables inside ThoughtSpot, such as naming, visibility, data type conversion, conditions, and so on. The first sync starts on the specified schedule.
Hourly sync
- Repeat
-
Select hourly.
Mandatory field.
- Starts
-
Accept the defaults, or set your own starting date and time for syncing.
Note that the timezone is in
UTC+00:00.Mandatory fields.
- Run the task every X hour(s)
-
Select the frequency of the sync.
The valid range is from 1 (default) to 12 hours.
Mandatory field.
- Alert notifications
-
Specify when to notify of the sync status:
-
Failures (default),
-
Success and Failures
-
Never.
- Email notifications
-
Write a list of recipients to whom success and failure notifications should be sent. Multiple email IDs can be specified as comma-separated values. You must provide this parameter to send an email for both failure and success scenarios.
-
Daily sync
- Repeat
-
Select daily.
Mandatory field.
- Starts
-
Accept the defaults, or set your own starting date and time for syncing.
Note that the timezone is in
UTC+00:00.Mandatory fields.
- Alert notifications
-
Specify when to notify of the sync status:
-
Failures (default),
-
Success and Failures
-
Never.
- Email notifications
-
Write a list of recipients to whom success and failure notifications should be sent. Multiple email IDs can be specified as comma-separated values. You must provide this parameter to send an email for both failure and success scenarios.
-
Weekly sync
- Repeat
-
Select weekly.
Mandatory field.
- Starts
-
Accept the defaults, or set your own starting date and time for syncing.
Note that the timezone is in
UTC+00:00.Mandatory fields.
- Days of the week
-
Select the days of the week when you want to sync.
For example, you may select only Monday, or only Monday through Friday.
Mandatory field.
- Alert notifications
-
Specify when to notify of the sync status:
-
Failures (default),
-
Success and Failures
-
Never.
- Email notifications
-
Write a list of recipients to whom success and failure notifications should be sent. Multiple email IDs can be specified as comma-separated values. You must provide this parameter to send an email for both failure and success scenarios.
-
Monthly sync
- Repeat
-
Select monthly.
Mandatory field.
- Starts
-
Accept the defaults, or set your own starting date and time for syncing.
Note that the timezone is in
UTC+00:00.Mandatory fields.
- Day of the Month
-
Select the days of the month when you want to sync.
Mandatory field.
There are two basic approaches:
- Cardinal day
-
Click the Day selector, and choose by date of the month from drop down menu.
For example, select
15to run sync on 15th of each month. - Ordinal day
-
Click the The selector, an choose one of First(default), Second, Third, Fourth, or Last. Then choose one of the days of the week, Sunday through Saturday.
- Alert notifications
-
Specify when to notify of the sync status:
-
Failures (default),
-
Success and Failures
-
Never.
- Email notifications
-
Write a list of recipients to whom success and failure notifications should be sent. Multiple email IDs can be specified as comma-separated values. You must provide this parameter to send an email for both failure and success scenarios.
-
Does not repeat
- Repeat
-
Select Does not repeat.
Mandatory field.
- Alert notifications
-
Specify when to notify of the sync status:
-
Failures (default),
-
Success and Failures
-
Never.
- Email notifications
-
Write a list of recipients to whom success and failure notifications should be sent. Multiple email IDs can be specified as comma-separated values. You must provide this parameter to send an email for both failure and success scenarios.
-
Map tables
To map the external tables to ThoughtSpot’s internal database, follow these steps:
-
Open the Map tables and columns interface by clicking the toggle to open.
-
The Internal ThoughtSpot storage tab opens by default.
-
Notice that the external database and table already appear, under External data source.
-
Specify the following information for internal ThoughtSpot storage:
- ThoughtSpot database
-
Select an existing ThoughtSpot database from the drop-down menu. If you wish to create a new database in ThoughtSpot, click TQL Editor, enter the
CREATE DATABASE my_database;command, and click Execute.
Mandatory field.
- ThoughtSpot schema
-
Select an existing ThoughtSpot schema from the drop-down menu. If you wish to create a new schema in your ThoughtSpot database, click TQL Editor, enter the
CREATE SCHEMA my_schema;command, and click Execute.
Mandatory field.
- New or Existing table
-
Mandatory field.
- Create a new table
-
Choose this option when you want to load data into a new table.
The system creates a new table automatically.
If you want the new table to have some special properties, create the table using the TQL Editor, proceed to Choose existing table, and then select the table you just created.
Click TQL Editor, enter the
CREATE TABLE my_table ...;command, and click Execute.Specify the table name.
- Choose existing table
-
Choose this option to load data into a table that already exists inside ThoughtSpot.
Select the table name from the drop-down menu.
- ThoughtSpot table
-
The name of the target table for data sync, inside ThoughtSpot.
Mandatory field.
Map columns
To map the columns of the external tables to columns in ThoughtSpot’s internal tables:
-
Scroll down to the Map the columns… section.
-
Specify the following information for columns:
-
Select (or deselect) columns for syncing into ThoughtSpot.
By default, all columns are selected. -
Search for columns by name; this is very useful for very wide tables.
-
Rename columns in the ThoughtSpot table, for easier search.
To make this change, click the pencil (edit) icon next to the name of the column. -
Change the data type of the column inside the ThoughtSpot table.
Click the down chevron icon to open the drop-down menu, and select a new data type.
For example, if you know you have integer data, change the default DOUBLE datatype to INT32. -
Set Primary keys of the table by toggling the selector to the 'on' position.
Note that several columns may be primary keys. -
Set the Sharding keys of the table by toggling the selector to the 'on' position.
-
Specify the Number of shards in the table.
-
Use Add new formula to transform your data before loading it into ThoughtSpot. Add logic to incorporate a frequently-used or complex formula at data ingestion, so ThoughtSpot doesn’t re-calculate it in every Answer and Pinboard.
Formulas support all row-level native database functions; we do not support aggregate functions.-
Click Add new formula.
-
In the Add new formula interface, name the formula and then build it by specifying the functions, columns, and parameters. Note that the support for functions depends on the support by the native database.
-
Click Add to finalize the formula. Notice this adds it to the list of mapped columns.
-
-
-
Save your work by clicking Save.
Alternatively, click Save and sync now to save your work and sync data at the same time.
Set sync properties
Basic sync properties
To set the sync properties, follow these steps:
-
Open the Advanced setup interface by clicking the toggle to open.
-
Choose the Sync properties tab.
-
Under Set sync properties, specify the following information:
- Condition
-
Add the condition that restricts the import of new rows into the ThoughtSpot table.
Optional field.
For example, to import rows of data from yesterday, enter the expressionDATE > DATEADD(TODAY(),-1).
To find the correct functions for the condition, click Expression editor, use it to create a valid expression, and click OK.
- Sync mode
-
Choose the sync mode, either Append or Overwrite.
Mandatory field.For Append or Overwrite, when the table has a primary key, ThoughtSpot uses UPSERT to update the new rows to the table.
- Append
-
This option adds new rows to the table.
- Overwrite
-
This option removes all existing rows, and then adds new rows to the table.
-
Save your work by clicking Save.
Alternatively, click Save and sync now to save your work and sync data at the same time. primary key.
Scripting for sync
To use scripting before or after the sync, follow these steps:
-
Open the Advanced setup interface by clicking the toggle to open.
-
Choose the Sync properties tab.
-
Scroll down to Advanced configuration, and click the toggle to expand.
-
Specify the following information:
- Wait for file
-
Specify the fully-qualified name of the file (directory path and file name) that must be present before sync can start.
- Pre-script
-
Add the script that you want to run before syncing.
Optional field.
For example, to drop data that is over 1 year old, enter the following expression:
DELETE from FACT_TABLE Where DATE < ADD_DAYS(TODAY(),-365).
To find the correct functions for the script, click Expression editor, use it to create a valid command (or several commands), and click OK.
- Post-script
-
Add the script that you want to run after syncing.
Optional field.
For example, to drop data that is over 1 year old, enter the following expression:
DELETE from FACT_TABLE Where DATE < ADD_DAYS(TODAY(),-365).
To find the correct functions for the script, click Expression editor, use it to create a valid command (or several commands), and click OK.
-
Save your work by clicking Save.
Alternatively, click Save and sync now to save your work and sync data at the same time.
Connector-specific sync properties
To modify connection-specific properties for sync, follow these steps:
-
Open the Advanced setup interface by clicking the toggle to open.
-
Choose the Sync properties tab.
-
Scroll down to Sync connector properties, and click the toggle to expand.
-
Specify the sync properties for Snowflake:
See Sync properties for details, defaults, and examples.
- Data extraction mode
-
Specify the extraction type.
- Column delimiter
-
Specify the column delimiter character.
- Enclosing character
-
Specify if text column data should be enclosed in quotes.
Optional field.
- Escape character
-
Specify the escape character if using a text qualifier in the source data.
- Escape unclosed field
-
Specify this if the text qualifier is mentioned. This should be the character which escapes the text qualifier character in the source data.
- Field optionally enclosed by
-
Specify if the text columns in the source data needs to be enclosed in quotes.
- Null If
-
Specify the string literal that indicates NULL value in the extracted data. During data loading, column values that match this string loaded as NULL in the target.
- Stage location
-
Specify a temporary staging server Snowflake has to use while DataFlow extracts data.
- Max file size
-
Specify the maximum size of each file in the stage location, in bytes.
- Parallel threads
-
Specify the number of parallel threads to unload data.
- Fetch size
-
Specify the number of rows fetched into memory at the same time. If the value is 0, system fetches all rows at the same time.
- Max ignored rows
-
Abort the transaction after encountering 'n' ignored rows.
- TS load options
-
Specify the parameters passed with the
tsloadcommand, in addition to the commands already included by the application.
-
Save your work by clicking Save.
Alternatively, click Save and sync now to save your work and sync data at the same time.
Related information


