Sharding
Sharding partitions very large tables into smaller, faster, more easily managed parts called data shards.
ThoughtSpot tables can be replicated or sharded. Replicated tables exist in their entirety, as the complete data set, on each node. Sharded tables consist of a single data set, divided into multiple tables, or shards. The shards have identical schemas, but different sets of data.
Note that sharding and loading tables into ThoughtSpot only apply to ThoughtSpot’s in-memory database. If you use Embrace, and store your data in another data warehouse such as Snowflake or Amazon Redshift, your data modeling is done in that data warehouse, and not in ThoughtSpot.
When to shard your data
By default, ThoughtSpot replicates tables.
To shard tables, you must add the PARTITION BY HASH ( ) clause to your CREATE TABLE statement.
Sharding your tables impacts the total amount of memory used by the table, its performance, and table loading times.
For example, you might shard a large table of sales data. You could divide a single sales table into shards that each contain only the data for a single year. The system then distributes these shards across several nodes. Requests for sales data are dispersed both by the year and the location of the shard in the node cluster. No single table or node is overloaded, improving both query performance and system load.
To optimize ThoughtSpot performance and memory usage, you should shard very large fact tables whenever possible. If you have a large dimension table, more than 40 million rows, you might choose to shard it along with the fact table it is joined with. Sharding both the fact and dimension table(s) is known as co-sharding. Refer to Sharded dimension tables. Before co-sharding the fact and dimension tables, consult with your ThoughtSpot contact.
Table sizes and sharding recommendations
When you are considering which tables you need to shard, and how many shards to use, there are several key sizing guidelines to keep in mind. You may not be able to fulfill each of these requirements for every table you shard. The most important requirement is that the number of shards for a given table take up less than or equal to 60% of your total available CPU.
-
60% of CPU: The number of shards for a given table should not take up more than 60% of your total available CPU. When possible, the number of shards should be well under 60%, for queries that involve multiple sharded fact tables.
60% of CPU is a best practice. If necessary, you can use up to 80% of your available CPU. Consult with your ThoughtSpot contact before choosing a sharding strategy that requires 80% of your available CPU for a given table. -
Number of rows per shard: Ideally, each shard should host about 15-20 million rows of data. So, if your table is under 20 million rows, you do not need to shard it. You should not have more than about 20 million rows of data on each shard.
-
Ideal number of shards: The ideal number of shards is the number of rows in a table divided by 20 million. So, if your table has fewer than 20 million rows, you do not need to shard it. However, if the ideal number of shards is more than 60% of your available CPU, you should ensure that you use less than 60% of your available CPU, rather than having the ideal number of shards.
-
Maximum number of shards: As a best practice, a given table should not have more than 1000 shards. This applies even if 60% of your CPU is above 1000. If you feel that you need more than 1000 shards for a given table, consult with your ThoughtSpot contact.
-
The number of shards should be a multiple of the number of nodes: To ensure equal distribution of data across all nodes, so that none of your nodes sits idle, the number of shards should be a multiple of the number of nodes. So, for a 12-node cluster, for example, a table could have 12, 24, 36, or 48 shards, and so on.
-
Minimum number of shards: Because the number of shards should be a multiple of the number of nodes, the minimum number of shards is the number of nodes. For a 12-node cluster, you should not have fewer than 12 shards.
This requirement may be difficult to achieve on large clusters with a high number of nodes. For example, you may have a table with 200 million rows on a 24 node cluster. Based on the guideline of 20 million rows per shard, this table should have 10 shards. 10 is not a multiple of 24. However, you may also have several very large tables on this cluster, with more than 1 billion rows. These 1 billion row tables can have at least 24 shards while fulfilling the 20 million rows per shard requirement, but the 200 million row table cannot. If you do not have these very large tables in your cluster, but you do have a high number of nodes, you might choose to have fewer than 20 million rows per shard, to ensure equal distribution of data. Consult with your ThoughtSpot contact if you are unsure how to handle sharding on your large cluster.
Sharding recommendations example
Let’s use an example to see how the 6 guidelines listed above in Table sizes and sharding recommendations work.
You have a fact table with 2.4 billion rows. Your cluster has 24 nodes, and 56 CPU cores per node.
-
Determine the ideal number of shards:
Number of rows/20 million
2.4 billion/20 million = 120
-
Determine 60% of the number of available CPU cores:
Number of nodes*Number of CPU cores per node*.6
24*56*.6 = 806.4
-
Compare the ideal number of shards with 60% of the number of available CPU cores:
120 is less than 806.4, so you have enough CPU cores to shard this table with the ideal number of shards.
-
Ensure that the number of shards is a multiple of the number of nodes, and therefore higher than the minimum number of shards for a given table:
Number of rows/ Number of shards must equal a whole number to allow you to distribute shards equally among the nodes.
120/24 = 5. 5 is a whole number.
-
Ensure that the number of shards is under 1000:
120 is under 1000.
In summary: You can shard this table by the ideal number of shards; 120, in this case, because 120 is less than 60% of your total available CPU, it is a multiple of the number of rows, and it is under 1000.
If the table had 2.6 billion rows, the ideal number of shards would be 130. However, 130 is not a multiple of 24, so 120 would still be the best number of shards for this table.
How to shard
Sharding is a type of partitioning.
It is sometimes called Horizontal partitioning.
The term sharding is particular to situations where data is distributed not only among tables, but also across nodes in the system.
To create a sharded table, add the PARTITION BY HASH ( ) clause to your CREATE TABLE statement.
TQL> CREATE TABLE
...
PARTITION BY HASH (96) KEY ("customer_id");Note the following parameters, specified as 96 and "customer_id":
- HASH
-
Determines the number of shards. In this case,
96. - KEY
-
Specifies how to assign data into the shards (shard key). In this case,
customer_id.
The recommended number of shards depends on various factors. See Table sizes and sharding recommendations.
If you omit the PARTITION BY HASH statement or if the HASH parameter is 1 (one), the table is unsharded.
The table is replicated instead, and physically exists in its entirety on each node.
This increases memory usage, since you are storing multiple copies of the same table.
If you want to use a table’s primary key as the shard key, specify that the table is to be partitioned by HASH on the primary key, as in this example:
TQL> CREATE TABLE "supplier" (
"s_suppkey" BIGINT,
"s_name" VARCHAR(255),
"s_address" VARCHAR(255),
"s_city" VARCHAR(255),
"s_phone" VARCHAR(255),
CONSTRAINT PRIMARY KEY ("s_suppkey")
) PARTITION BY HASH (96) KEY ("s_suppkey");How to choose a shard key
We recommended that you always specify the KEY parameter when HASH is greater than 1.
If you omit the KEY parameter in your CREATE TABLE statement, ThoughtSpot shards the table randomly.
|
ThoughtSpot does not have a default shard key.
-
If the table has no primary key, the sharding is unconstrained. You can choose any subset of columns that is valid for use as the primary key as the shard key. If you do not specify the shard key, ThoughtSpot implements random sharding.
-
If the table has a primary key, you must specify the
KEYparameter of thePARTITION BY HASHstatement. This shard key must be a subset of the primary key.
DO
...
CONSTRAINT PRIMARY KEY("saleid,vendorid”))
PARTITION BY HASH(n) KEY ("saleid");...
CONSTRAINT PRIMARY KEY("saleid,vendorid”))
PARTITION BY HASH(n) KEY ("vendorid");In the above examples, the table has a primary key.
The KEY parameters specified, saleid and vendorid, are subsets of the primary key.
In the below example, the table has a primary key.
The KEY parameter specified, locationid, is not a subset of the primary key, and therefore cannot be used as the shard key.
AVOID
...
CONSTRAINT PRIMARY KEY("saleid,vendorid”))
PARTITION BY HASH(n) KEY ("locationid");
When you shard a large table, you select a shard key from the table. This key exists in every shard. Choosing a shard key plays an important role in the number of shards and the size of any single shard.
Best practices for choosing a shard key
Here is a full CREATE TABLE statement.
CREATE TABLE "sales_fact"
("saleid" int,
"locationid" int,
"vendorid" int,
"quantity" int,
"sale_amount" double,
"fruitid" int,
CONSTRAINT
PRIMARY KEY("saleid", "vendorid"))
PARTITION BY HASH(96)
KEY ("saleid");
The shard key is a subset of the primary key. However, that is not the only guideline to follow when choosing a shard key.
-
If the table has a primary key, the shard key must be a subset of the primary key.
If the shard key is not a subset of the primary key, and the shard key changes, data with the same primary key may reside in different nodes. This impacts ThoughtSpot’s performance, and may result in incorrect query results.
You should not use a shard key that is not a subset of the primary key. If you use a shard key that is not a subset of the primary key, it is possible to get two versions of a record if the shard key for a record changes, but the primary key does not. In the absence of a unique shard key, the system creates a secondary record rather than doing a SQL MERGE (
upsert). These two versions of a record may result in incorrect results when you search your data in ThoughtSpot.If you try to use a shard key that is not a subset of the primary key, your
CREATE TABLEcommand returns an error. -
Choose a shard key that distributes data well across keys.
For example, suppose the table you want to shard has a primary key made up of
saleid,custid, andlocationid. The table has 10K sales, 400 locations, and 2000 customers. If 5K sales are in just two locations, you should not uselocationidas your shard key. If you uselocationidas your shard key, you have data in fewer shards, which impacts performance. Instead, you should usecustidandlocationid.As a more concrete example, suppose you want to shard a table of retail data. Many retailers have an increase in sales around the winter holidays. You should not use
dateas your shard key, because you may have five or ten times your usual number of daily transactions during the month of December. Usingdateas your shard key would result in data skew, and would impact performance.Here is an example of data skew, where
Los Angeleshas many more transactions than the average, so you should not usestore countyas your sharding key.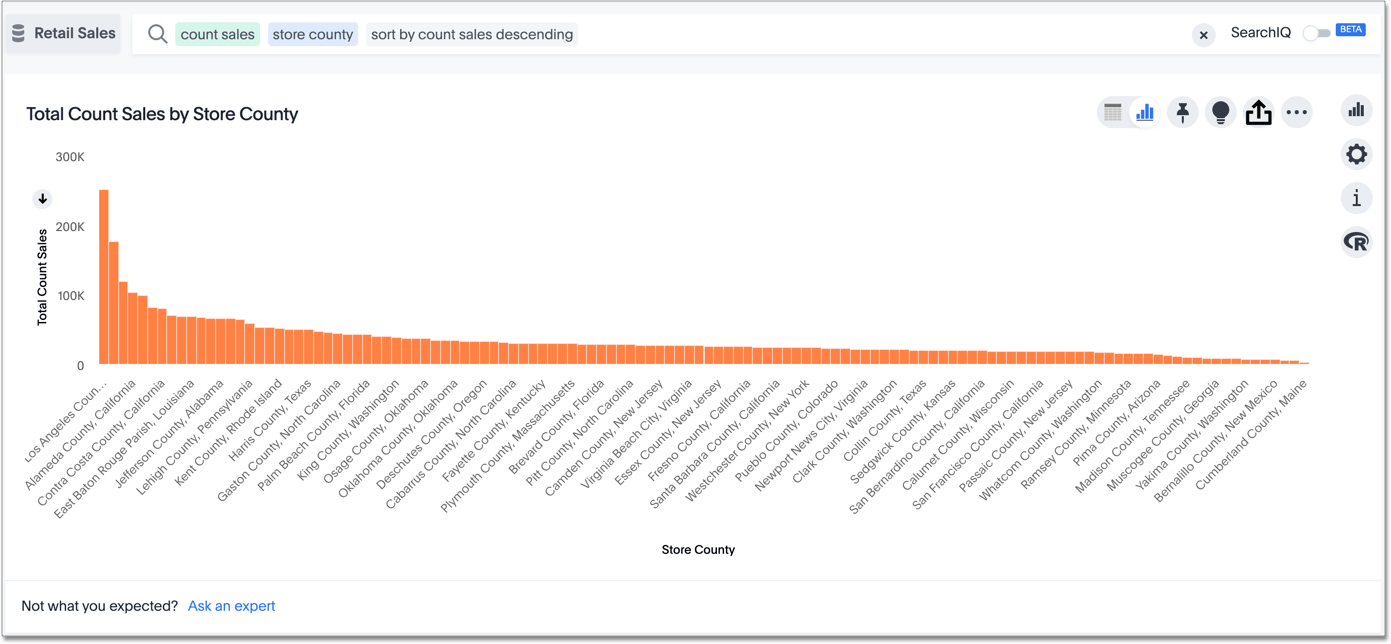
You may also have to clean up your data and any null values before sharding. For example, your retail data may have a
customercolumn. One of the values forcustomermay beunknown. A value likeunknownwould exist in many more transactions than a single customer name. A value likeunknown, or any null values, result in data skew, and impact performance. -
Choose a shard key that results in a wide variety of keys.
For example, suppose the table you want to shard has a primary key made up of
saleid,productid, andlocationid. The table has 10K sales, 40 locations, and 200 products. Even if the sales are evenly distributed across locations, you should not uselocationidin your shard key, because there are only 40 possible keys. Instead, usesaleidandproductidfor more variety. -
If you plan to join two or more tables that are both sharded, both tables must use the same shard key.
This guideline ensures better join performance. For example, if you have two tables and the primary keys are:
PRIMARY KEY("saleid,vendorid")on A +PRIMARY KEY("saleid,customerid")on BUse
saleidas the shard key when you shard both tables. -
If your primary key includes several columns, use all appropriate columns in the shard key.
Your primary key may include several columns. For example, suppose the table you want to shard has a primary key made up of
saleid,custid, andlocationid, as in the example in guideline three. The table has 10K sales, 40 locations, and 200 products. Based on the best practice outlined in guideline three (choose a shard key that results in a wide variety of keys), you should not uselocationidin your shard key. Bothsaleidandcustidare good shard keys, based on the four best practices mentioned above. Instead of picking one column to use as your shard key, use bothsaleidandcustid.
You can always use your primary key as a shard key. If you have trouble picking another shard key based on the above requirements and best practices, use your primary key.
Sharded dimension tables
In a typical schema, you’d have a sharded fact table, with foreign keys to small dimension tables. ThoughtSpot replicates these small dimension tables in their entirety and distributes them on every node. If your dimension table has more than 40 million rows, however, you may want to co-shard it with related fact tables. Consult with your ThoughtSpot contact before co-sharding.
If you have a large dimension table, replicating it and distributing it can impact the performance of your ThoughtSpot system. In this case, you want to shard the dimension tables and the fact table. Note that you can co-shard multiple fact tables and one or more dimension tables on the same shard key. ThoughtSpot can handle chasm traps.
When sharding both a fact table and its dimension table(s), (known as co-sharding) keep in mind the guidance for creating a shard key. Only shard dimension tables if the dimension table has more than 40 million rows, and the join between the fact and dimension tables uses the same columns. Specifically, the tables must:
-
be related by a primary key and foreign key
-
be sharded on the same primary key/foreign key
-
have the same number of shards
If these requirements are met, ThoughtSpot automatically co-shards the tables for you.
Co-sharded tables are always joined on the shard key.
Data skew can develop if a very large proportion of the rows have the same value for the shard key.
For example, you may have an unknown value for a customer column.
Many of the rows of a fact table may include this value, resulting in data skew.
Refer to sharding best practices to learn how to check for data skew.
You can view your row count skew from the ThoughtSpot application.
Go to admin, then System health, then data.
Choose the table you would like to view, and scroll to row count skew.
Use this number to calculate your row count skew ratio: row count skew / (total row count / number of partitions).
A row count skew ratio higher than 1 may require changes to your data modeling.
This example shows the CREATE TABLE statements that meet the criteria for sharding both a fact table and its dimension table:
TQL> CREATE TABLE products_dim (
"id" int,
"prod_name" varchar(30),
"prod_desc" varchar(100),
PRIMARY KEY ("id")
)
PARTITION BY HASH (96) KEY ("id")
;
TQL> CREATE TABLE retail_fact (
"trans_id" int,
"product_id" int,
"amount" double,
FOREIGN KEY ("product_id") REFERENCES products_dim ("id")
)
PARTITION BY HASH (96) KEY ("product_id")
;
Joining two sharded fact tables
You can also join two sharded fact tables with different shard keys, but it is not recommended. This is known as non co-sharded tables. It may take a while to join two tables sharded on different keys, since ThoughtSpot has to redistribute your data. Therefore, ThoughtSpot recommends that you use a common shard key for two fact tables.
You are not limited by the column connection or relationship type.
Sharding best practices
There are several best practices related to sharding.
-
Shard your tables before loading data.
Your data loads faster if you have already sharded the tables. Use the
CREATE TABLEcommand to specify how you want your tables sharded, but do not load any data. After you shard the tables, your data loads faster. -
You may need to re-evaluate your sharding over time, as your data evolves. Take a look at how your sharding impacts performance after you change your data significantly. Data also changes naturally over time, so you should re-evaluate sharding at a regular cadence.
To evaluate your sharding strategy, run the following script. It checks for over- or under-sharded tables on your cluster.
-
Log in to your cluster on the command line.
$ ssh admin@<cluster-IP>
-
Run the following script to check for over- or under-sharded tables.
$ /usr/local/scaligent/release/bin/sharding_diagnostics.sh
-
Adjust your sharding strategy appropriately. See Change sharding on a table.
Note that resharding automatically loads data into a new incarnation of the table you sharded. You do not need to reload the table’s data.
-
-
Check your
row count skewratio when you re-evaluate sharding.You can view your
row count skewfrom the ThoughtSpot application. Go to Data > Usage > Data. Find the correct table name, and scroll torow count skew. Use this number to calculate your row count skew ratio: row count skew / (total row count / number of partitions). A row count skew ratio higher than 1 may require changes to your data modeling.


