Flexible aggregation functions
The primary purpose of the group_aggregate function is for level of detail analysis. As this function generates a sub-query as a SQL Common Table Expression (CTE), this can be used for advanced edge cases beyond this primary purpose.
The group_aggregate function provides greater controls than specific group functions like group_sum and group_max. This flexibility is primarily in relation to how grouping columns or filters will be accepted or ignored as part of the final calculation. The group_aggregate function also allows for the definition of an outer aggregate.
This function includes three input variables:
-
The aggregation type and the column to be aggregated.
-
How grouping columns will be accepted or ignored.
-
How filters will be accepted or ignored, or if a filter is always applied.
Instance modes
Since the 9.3.0.cl release, two query generation modes exist. Note that all new clusters have the new pattern defined, and that an exception is required to revert to the legacy behavior. For risk-mitigation purposes, this is slowly being applied across all instances.
To explain this behavior, let’s assume that the user wishes to answer the following business questions:
-
What are my sales by store?
-
What are my sales by region?
-
What is the contribution of store sales to the region?
In order to answer questions 2 and 3, we need level of detail calculations.
For sales by region, we would use the following formula:
sales of region = group_aggregate ( sum ( sales ) , { region } , query_filters ( ) )For contribution of store sales to region, we would use the following formula:
sales percentage of region = sum ( sales ) / sum(group_aggregate ( sum ( sales ) , { region } , query_filters ( ) ))The following table is an example of the resulting answer. Note that the granularity of the search is at the region and state level. Therefore, the total sales value is calculated at this level. The sales of region column shows a repeating value where the total is the amount for the entire region.
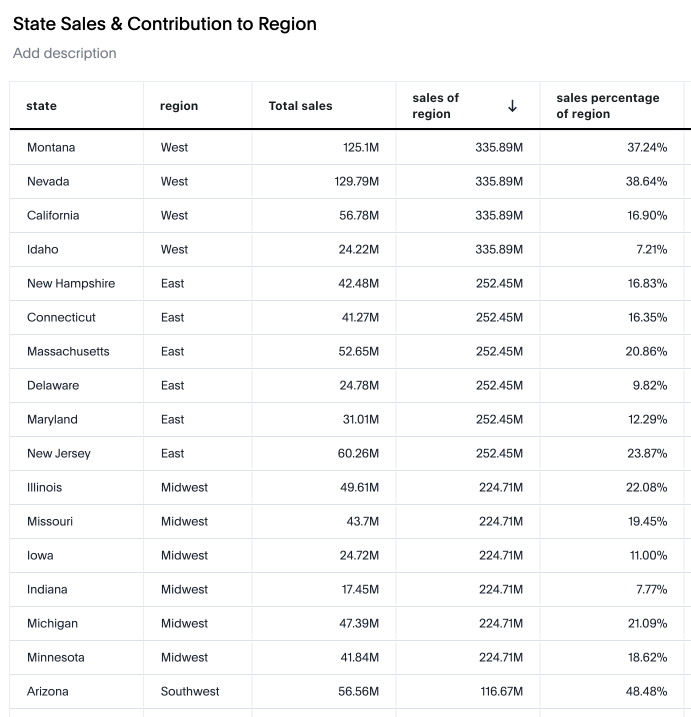
Respect fixed grouping columns (new and default behavior)
As per the example formula for sales of region, the calculation is fixed at the regional level. Therefore, if region is removed from the search or not visualized in a chart, the result does not change. That is, the result is still calculated at the regional level.
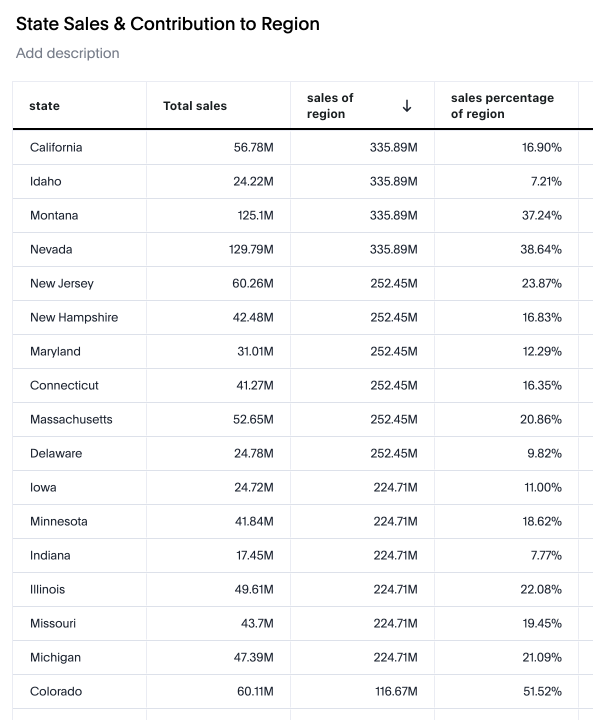
Reaggregate unused grouping columns (legacy behavior)
The legacy behavior would only fix the results when the column is defined in the search or as a visualized column. Therefore, if the region column is removed, the result is reaggregated as total sales. This behavior is incorrect as the analyst has defined a fixed definition. The contribution is the contribution of state sales to total sales.
Highlighted behavior changes
The following are highlights in formula changes between the legacy mode and the new mode.
Ratio definition
It is important to define the outer aggregation when calculating rations. The legacy behavior would include a default aggregation. As the new behavior respects the fixed grouping column, this should be defined in the formula.
sum ( sales ) /group_aggregate ( sum ( sales ) , { region } , query_filters ( ) )sum ( sales ) / sum(group_aggregate ( sum ( sales ) , { region } , query_filters ( ) ))Calculating ratios with group functions
To correctly calculate ratios using group functions in ThoughtSpot, you must wrap the group_aggregate function with an explicit outer aggregation, such as sum or average.
sum(group_aggregate(sum(sales), {sku}, query_filters())) / sum(group_aggregate(sum(sales), {item_category}, query_filters()))
This ensures that the results of the group_aggregate are properly re-aggregated to the desired level, preventing ambiguity and ensuring consistent, accurate ratio calculations regardless of the search context. Always use an explicit outer aggregation when using group_aggregate in ratio formulas.
Optional grouping columns
A dynamic denominator is useful where the resulting ratio is updated based upon the grouping columns included in the search. That is, if the user adds the region column, then the contribution ratio should be the state’s contribution to region. If the user removes the region column, then the contribution should be the state’s contribution to the total.
As the legacy behavior did not respect the fized column attributes, formulas were written to simulate this behavior. The new query pattern requires that the data analyst explicitly defines this optional grouping.
sum ( sales ) / sum(group_aggregate ( sum ( sales ), query_groups(region),query_filters ( ) ))Groups and filters
Flexible group aggregate formulas allow for flexibility in both groupings and filters. The formulas give you the ability to specify only groupings or only filters.
Query groups
With query_groups () + {attribute_column} or query_groups () - {attribute_column}, you can aggregate results while including or excluding a column from the original search. The query_groups() function returns all attribute columns defined in the base search when the table view is displayed.
Columns are not included in the query_groups definition when a chart is displayed and the column is not visualized.
|
If, for example, you use the condition query_groups() - {region, sku, name}, this changes the level of detail for the group aggregate formula. In this scenario, region, sku, and name have been removed. If these columns are not included in the base search, then this definition is ignored. Under the new logic, the {region, sku, name} condition fixes the level of detail for the group by columns to the columns defined.
You can combine options to both add and remove columns like in the following example: query_groups() + {region} - {sku, name}.
Regarding dates, when query_groups() is defined, the date period defined in the search will be passed into the group function. Assuming the search is monthly, then the group function will also be at the monthly grain. You can use date functions to change the grain, such as {start_of_year(transaction date)}.
Query_groups optional grouping columns
The query_groups function is used in group_aggregate, first_value, and last_value functions. This returns a list of columns/ attributes that have been included in the search. This allows for flexible inclusion and exclusion of grouping columns using the following syntax:
-
query_groups(): includes all grouping columns. -
{region, department, store}: specifies a list of grouping columns explicitly. These columns can be considered as the fixed level of detail for this formula. -
query_groups() - {customer_name, customer_region}: includes all grouping columns except customer_name and customer_region. -
query_groups() + {order_id}: includes all grouping columns and ensures order_id is always included. -
query_groups() - {customer_name} + {order_id}: combines the inclusion of order_id and exclusion of customer_name.
You can now define an explicit optional list of grouping columns using the following syntax: `query_groups(region, department, store). This ensures that only the specified columns are included, if they are present in the query.
Previously, this capability required manually excluding all other columns from the underlying Model. This approach was difficult to maintain, as new columns added to the Model would also need to be added to the exclusion list for every formula.
Query filters
Query filters support the ability to define default filters, accept filters, or ignore filters.
Use the following syntax:
* query_filters(): accepts all filters applied in the search.
* query_filters() + {filter condition}: accepts all filters and includes a specific filter, such as ship mode = car.
* query_filters() - {column}: ignores filters from a specific column or columns.
* {column}: only accepts filters for a specific column or columns.
With query_filters() + {filter condition} or query_filters() - {filter condition}, you can aggregate the results while including or excluding a filter condition. Consider the filter condition Ship Mode - 'car'.
For a search on Category Customer ID sales by customer id and category Ship Mode='car', you can add a formula to calculate sales by category for each customer. For example, the formula sales by Customer ID and Category= group_aggregate (sum(Sales), {Category, Customer ID}, query_filters()+{Ship Mode='air'}). In this case, the results will be aggregated based on the dimensions
Category and Customer ID and the filters air and car.
With query_filters() - {column}, you will be able to aggregate the results while removing any expression related to a column. For a search on Customer ID sales by customer id and category Ship Mode='car', you can add a formula to calculate sales for each customer while ignoring the filter on a column. For example the formula sales by Customer ID and Category= group_aggregate (sum(Sales), {Customer ID, Category }, query_filters()-{Ship Mode}). In this case, the results will be aggregated based on the dimensions in the search (Customer ID) and any filter related to Ship Mode will not be considered while aggregating the results.
You can also insert the name of the sole field you want to filter on. For example, if you would like to determine how many stores a certain product was sold in during a given time period, expressed as a ratio of total available stores. In order to calculate the total available stores you require a group_aggregate function that will accept the filters associated with transaction date (for example, this year, last six months, august), and ignore filters from other fields.
Users can specify the formula as group_aggregate(count(storeid),query_groups, {date}), and the formula will automatically ignore all unrelated filters in the search bar.
Finer-grained group formula results
The flexibility of groupings for group formulas enables you to create a formula that generates a computed column that is finer or coarser than the search itself. Note that ThoughtSpot by default respects the level of detail defined in the formula results.
For example, you can have a search that shows total yearly sales and a formula that computes total sales for each month (a finer-grained calculation than the search).
In such cases, if an additional aggregation is specified by the formula, the results get reaggregated.
Reaggregation can be applied in either of these ways:
-
You can add an aggregation keyword just before a formula column in a search. For example, in this search we’ve added the keyword min just before our formula for
monthly_sales:sum revenue yearly min monthly_sales
where, the
monthly_salesformula is written as:group_aggregate(sum(revenue), {start_of_month(date)}, {}) -
You can create a separate formula, such as in this search for:
sum revenue yearly min_monthly_sales
where, the
min_monthly_salesformula is written as:min(monthly_sales)
If no aggregation is specified, then the search query aggregates to the level of detailed defined in the search bar. In the following search:
sum revenue yearly monthly_sales
the original query is computed at a yearly grain instead of monthly.
Reaggregation scenarios
Some scenarios require aggregation on an already aggregated result.
For example, computing minimum monthly sales per ship mode, requires two aggregations:
-
the first aggregation of sum to compute total monthly sales per ship mode.
-
the second aggregation of min to compute the minimum sale that happened for any given month for that ship mode.
An example of this is this search:
ship mode min monthly_sales
where the formula monthly_sales is written as:
group_aggregate(sum(revenue), query_groups() + {start_of_month(date)}, {})
For more extensive examples of using the group-aggregate function, we encourage you to see Reaggregation scenarios in practice.
Related information
For more examples of flexible aggregation, see the group_aggregate function in the Formula function reference.
To learn about aggregation formulas in general, see Overview of aggregate formulas and Group aggregation functions.
To understand group aggregate query filters, see Aggregate filters.
To learn about how the
group-aggregatefunction can be used within your business practice, we encourage you to see Reaggregation scenarios in practice.


